
Ever felt overwhelmed planning your day in a foreign city? Imagine you are on a solo trip, and you have to plan everything by yourself starting from looking for a breakfast place. You don’t want to spend too much, want to optimise your travel time; don\’t want to end up walking a lot or taking cabs unnecessarily, want to avoid going to a very blah touristy place, want to figure out the gems in the city etc. Even with a group of friends, you probably have a conflict of interest and end up spending a lot of time sitting in one place trying to avoid the hazard of finding new activities to do.
Clearly there is a lot of decision making involved in such planning, much more than selecting a hotel or a flight. Since it is too complex for a user to weigh all the possible alternatives and assign probabilities or expectations to each of them and conclude a final decision, this decision making gets mostly dominated by the instinctive or behavioural decision making. That is to say, most of us resort to the rapid and frugal way of decision making in such cases. Look for an alternative, weigh its feasibility with the constraints and either choose it or move on from it to the next alternative in line. Success of doing so is very much dependent on the expertise of the user itself, and hence the process is not always reliable. Whereas a rational decision maker would follow a three-step process of (a) analyzing the feasibility of the alternative, then of (b) pondering the desirability of the alternative, and finally (c) choosing the best alternative by combining both desirability and feasibility. At MeTripping, we try to reduce the cognitive load of making a satisfactory decision and offer rational decision making. However, an overall decision making process possesses a strong cultural/behavioural component that influences the decision style, perception and attitude of the decision makers. Capturing this cultural component has been our utmost priority and most challenging at the same time. In an effort to capture this, we have introduced certain user inputs which let us understand the user’s feelings a little more and work in sync.
By gathering the user information and data from our official partners, we try to recommend a feasible and best quality daily activity itinerary.
Activity Data: For now, we have obtained the organized, paid activity data from Viator inventory. This data contains the information about the activities in the form of text descriptions along with few additional details such as cost and duration of the activity etc. However, sourcing this data is just a cog in the wheel and suggesting these activities to the users in the form of an itinerary remains extremely challenging mainly because of the following reasons
Challenges
- While suggesting an activity you want to match the activity type with the user\’s trip intent. We try to understand the user’s intent from the user input itself, but learning the intent information from an activity text is still not that straightforward
- Activity data does not explicitly tell us what all points of attraction it covers, which is necessary in order to avoid suggesting duplicates such as two activities around the common points of attractions etc
- Single attraction point can have multiple activities around it and figuring out the best activity offered by a vendor for that attraction remains challenging
- Simply creating a user relevant set of activities is not enough. A lot of cognitive load on the user is still left if the feasibility of those activities has not been taken care of. For example, activities that are relevant to the user might not be doable because of their timings, cost or distance from the user’s accommodation etc
- For suggesting a doable set of activities understanding of user’s budget for activities is really important, which is hardly ever available explicitly
- To suggest a complete itinerary, you want to optimise travel time while making sure that you don’t miss good activities. As an example, your good activities might be on the two corners of the city and the user might not have enough time to cover both or lets say there are other activities which are of slightly lesser quality but are easy to commute to. Figuring out such trade-offs is a huge challenge
Behind the scenes
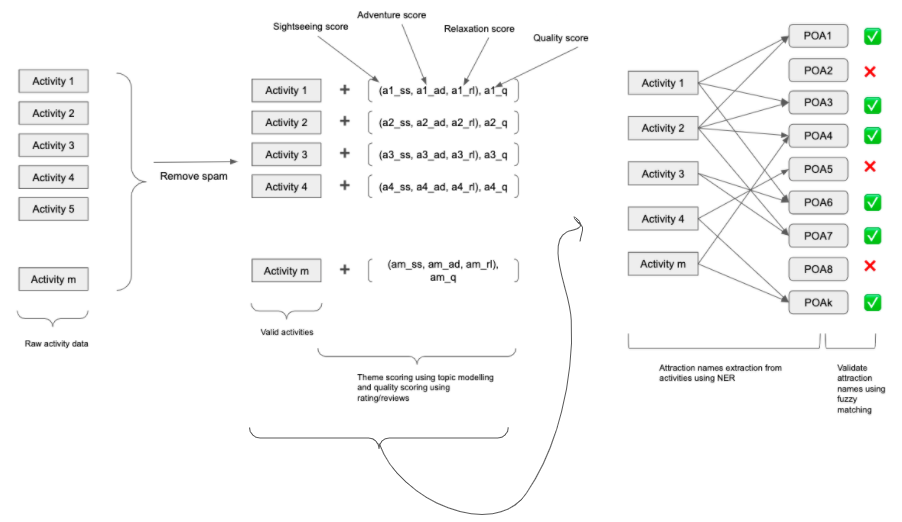

Extracting details from the activity text
Activity data that we gather does not have everything we need in order to make recommendations ready made. And the information about an activity is in the form of text, and it may or may not contain all the information we need. However, using NLP techniques, we are capable of extracting most of the information from most of the data. Following are the details we are looking for:
- Theme type of an activity, i.e.relaxation, adventurous, sightseeing. This is inline with what we take as a user input to understand user\’s intent
- All the points of attractions an activity covers. This info is required for multiple reasons,
- To make sure we don’t suggest multiple activities for a single attraction
- To cluster the activities as per the lat-longs of the attraction points they cover
- To factor in the quality of the attraction points an activity covers while scoring the activity
- To figure out must see types of attractions etc
- Open/Close timings of the activities, age-group allowed, pickup-dropoff location, cost, duration etc. These minor details remain important while filtering the user relevant activities as well as while creating an itinerary
Further explanation on how the above are retrieved is as follow
Classification of activities,
into aforementioned themes is achieved using ways of topic modelling. A brief introduction about topic models:
Topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body. In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract \”topics\” that occur in a collection of documents. Each document in the text is considered as a combination of topics and each topic is considered as a combination of related words. The \”topics\” produced by topic modelling techniques are clusters of similar words. A topic model captures this intuition in a mathematical framework, which allows examining a set of documents and discovering, based on the statistics of the words in each, what the topics might be and what each document\’s balance of topics is. Earliest topic model was developed in 1998. We have in particular used Latent Dirichlet Allocation (LDA) which was developed by David Blei, Andrew Ng and Michael I. Jordan.
How does LDA work?
In brief LDA assumes a fixed set of topics and tries to map a document to a subset of these topics such that most of the words in the document are represented by those topics. LDA assumes a generative probabilistic model of a corpus. The basic idea is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words.
Mathematically, let’s say we define a corpus with a matrix D of dimension MxN, where M is the number of documents and N is the number of words, i.e, vocabulary size . Each cell of matrix D, dij represents the frequency of the jth word in the ith document of the corpus. Now LDA factorizes this matrix D into two matrices, M1 and M2, where M1 is a document-topic matrix and M2 is a topic-word matrix.

LDA assumes a generative process for each document in the corpus using Dirichlet distribution of these two matrices. More detailed implementation can be studied in this original paper by the LDA pioneers.
Figuring out the attraction points,
is done using Named-Entity Recognition methods. To further validate the extracted attraction points against the world’s actual attraction points, a fuzzy matching algorithm is developed for better handling of the problem at hand.
Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a sub-task of information extraction that seeks to locate and classify named entities in text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
We have used the Stanford named entity recognizer in our case. Stanford tagger is considered as a benchmark in the industry for its speed and accuracy. It\’s also known as CRFclassifier since it\’s based on conditional random field models. CRFs come from a general class of algorithms called graphical models and are more favourable than classic hidden Markov based models because they manage to learn from the dependency among specific events. Stanford tagger provides an implementation of a linear chain conditional random field sequence model. More details on this can be found here.
For the fuzzy matching and validation of the extracted attraction names we have used n-grams of the names and compute the one to one match using cosine similarity of TF-IDF vectors of produced n-grams.
Similarity between activities
The idea is to be able to recommend activities which are similar to an already suggested/accepted activity and to avoid suggesting similar activities as part of one itinerary, unless specifically required by the traveler
Two activities can be stated similar when,
- Either they cover the same points of attractions
- Or they are similar in style, i.e., both are hiking tours etc
Activity similarity score defined by us is meant to capture both kinds of similarities. This is done in addition to the theme similarity score we anyway get as mentioned above.
In the process of calculating the style similarity, the activity text is converted into feature vectors and similarity is defined as the distance between those feature vectors. There are many ways to do the same, starting from simple techniques (focus on lexical similarity) to more complex ones (tend to focus on finding semantic similarity). Can be added here once the approach is finalised.
Clustering of activities
The idea is to cluster the activities in order to optimize the route taken by the user while performing those activities. So it would be ideal to have lat-longs of the pick-up locations for the activities to perform clustering. Figuring out pick-up locations is not possible for all the activities due to the unavailability of the data, hence locations of attraction points for such activities were used as a proxy. Using Open Street maps we get lat-longs data for all the identified locations and further clustering is done using the DBSCAN algorithm.
DBSCAN, Density based spatial clustering of applications with noise, is a well-known data clustering algorithm commonly used in data-mining and machine learning. It is a density based algorithm which takes a set of points in n-dimensional space and groups together points that are close to each other based on a distance parameter and a minimum number of points required to form a dense region. The latitude and longitude pairs are clustered not according to the euclidean distance but the 3-D circumferential distance between points to ensure uniformity in cluster generation all across the globe. In contrast the euclidean method would yield skewed results at very high and very low latitudes and would not have a map rolling feature at end points of longitudes.
Scoring the activities
Scoring activities helps us in choosing the best out of many activities for a single attraction point and lets us rank all the activities to choose the best set for the user.
To score an activity, we’ve developed a scoring function which takes into account the number of reviews, user reviews and user ratings for the activity and the attraction points it covers.
Filtering a set of activities
From a number of activities, we want to filter the activities around which we want to create an itinerary as per the scoring mentioned above. The fundamental rule is to prioritise quality over quantity, i.e., rather than packing a user\’s day with a number of not-so-great, cheap activities we try to prioritise a smaller set of better quality activities.
During this process we need to keep in mind the user budget and time available for activities to the user. As an input from the user, we take an overall budget for the trip. Our one of the biggest challenges revolves around assigning budgets for different verticals of a trip such as accommodation, travel and in destination expenditure. Budget for activities is a part of in destination expenditure. We calculate this budget by looking at the overall budget user has specified, trip intent and the cost of activities at the destination. The available time for the activities is calculated keeping the user\’s flight timings in check.
Satisfying both budget and duration parameters simultaneously is extremely challenging. After sorting the activities as per their quality score, there is usually a tradeoff between less number of expensive activities and more number of inexpensive activities. And this is more so an issue when the trip is long and there are only a couple of top activities which consume the entire activity budget. So while choosing a set, we also look at the cost per unit time factor for each activity, and best quality activities are selected such that both time and budget are optimised.
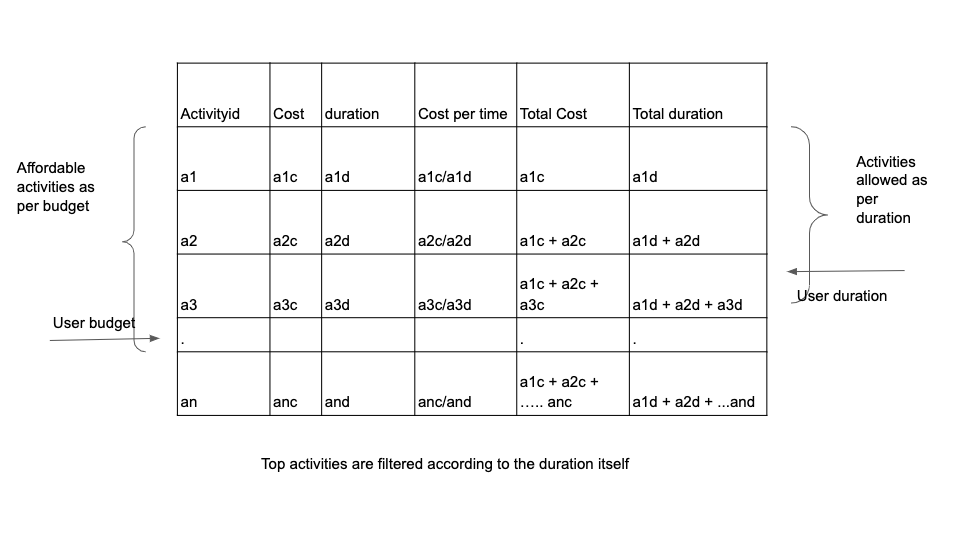

Activity itinerary
An activity itinerary is meant to tell you what activities to do at what timings. As mentioned earlier, we create activity clusters on the basis of their proximity to each other to optimise the travel. Ideal scenario would be when a user can complete a single cluster in one go. Although we have taken the duration of the activities and time available to a user into the account while selecting top activities, this remains challenging because of the opening/ closing timings of various activities/ attractions. Having the total duration of the filtered activities less than the time available in the day for the user doesn’t guarantee the feasibility of those activities on that day. A worst case scenario would be when you have all chosen activities occurring at the same time. Therefore, the utmost priority is to be able to map these activities onto different travel days and create a daily itinerary making sure the activities don’t overlap.

Closing thoughts
Decision making should be the end of deliberation and start of action, and thats what we try to achieve by putting an actionable solution in front of the user. Like any decision making which should not be about optimising each and every factor but to produce a satisfactory outcome, this solution also aims for that. Most importantly we have build our models on normative, rational decision making theory which focuses on how decision makers should decide rather than the descriptive, psychological decision making theory which focuses on how individuals decide. Hence, those discrepancies or disagreements can still be observed for a given solution.
Credits:
I would like to thank the team who has worked tirelessly for the development of the above mentioned end-to-end solution @Pranjal Gupta @Somu Prajapati @Sachit Agrawal. Thank you.